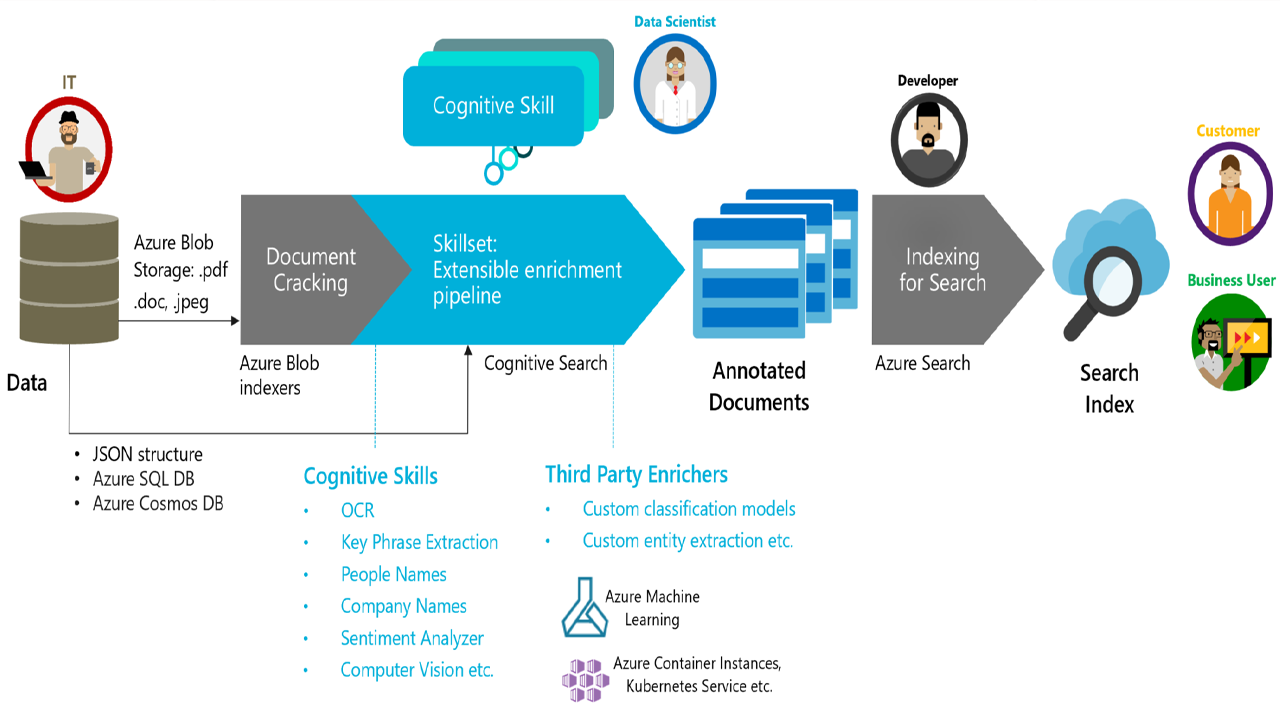
Chuỗi bài viết sẽ cung cấp những khái niệm cơ bản, cách thức cấu hình trên cả giao diện đồ họa và dòng lệnh cùng ứng dụng và các best practice trong quy trình bảo mật dữ liệu của tổ chức.
Sensitive Information Types (SIT) là gì?
Sensitive Information Types (SIT) là các mẫu nhận diện do Microsoft Purview cung cấp để tự động phát hiện thông tin nhạy cảm trong tổ chức. SIT giúp xác định những dữ liệu như số thẻ tín dụng, số tài khoản ngân hàng, số an sinh xã hội (SSN), tên riêng, địa chỉ IP,…, dựa trên việc dò tìm các mẫu ký tự hoặc từ khóa đặc trưng cho các loại dữ liệu đó.
Microsoft đã tích hợp sẵn hơn 300 loại SIT (built-in SIT) phục vụ nhiều mục đích khác nhau, đồng thời cho phép tổ chức có thể tạo mới các SIT tùy chỉnh (custom SIT) nếu các mẫu sẵn có không đáp ứng được nhu cầu.
Microsoft Purview cung cấp SIT như một phần của chức năng phân loại dữ liệu. Đây là bước đầu tiên giúp tổ chức nhận diện và phân loại dữ liệu nhạy cảm nằm trong hệ thống. Sau khi được nhận diện bằng SIT, các dữ liệu nhạy cảm có thể được áp dụng chính sách bảo vệ thích hợp.
SIT sẽ được sử dụng ở đâu?
Các SIT được sử dụng rộng rãi trong nhiều dịch vụ của Microsoft 365/Purview nhằm bảo vệ dữ liệu nhạy cảm của tổ chức. SIT là thành phần cốt lõi trong các giải pháp sau:
- Các chính sách chống thất thoát dữ liệu (Data Loss Prevention)
- Các nhãn nhạy cảm và chính sách tự động gán nhãn (Sensitivity Labels & Auto-labeling)
- Các chính sách về nhãn lưu giữ (Retention label)
- Các chính sách về quản lý rủi ro nội bộ (Insider Risk Management)
- Các chính sách về tuân thủ giao tiếp (Communication Compliance)
- Microsoft Priva
SIT trở thành công cụ chung để nhận diện dữ liệu nhạy cảm trên toàn bộ hệ sinh thái Microsoft 365 từ Exchange, SharePoint, OneDrive, Teams cho đến Power Platform,…
Các thành phần quan trọng của một SIT?
Mỗi SIT được định nghĩa bởi một số thành tố cơ bản gồm:
Primary Element – yếu tố chính
Yếu tố chính mà SIT sẽ tìm để xác định dữ liệu nhạy cảm. Thành phần chính có thể được định nghĩa bằng một biểu thức chính quy (RegEx), một danh sách từ khóa cố định (keyword), một từ điển thuật ngữ (dictionary), hoặc sử dụng một hàm có sẵn của Microsoft (function).
Đây là thành phần bắt buộc trong một SIT và nếu nội dung không khớp yếu tố chính, SIT sẽ không kích hoạt.
Supporting element – yếu tố bổ trợ
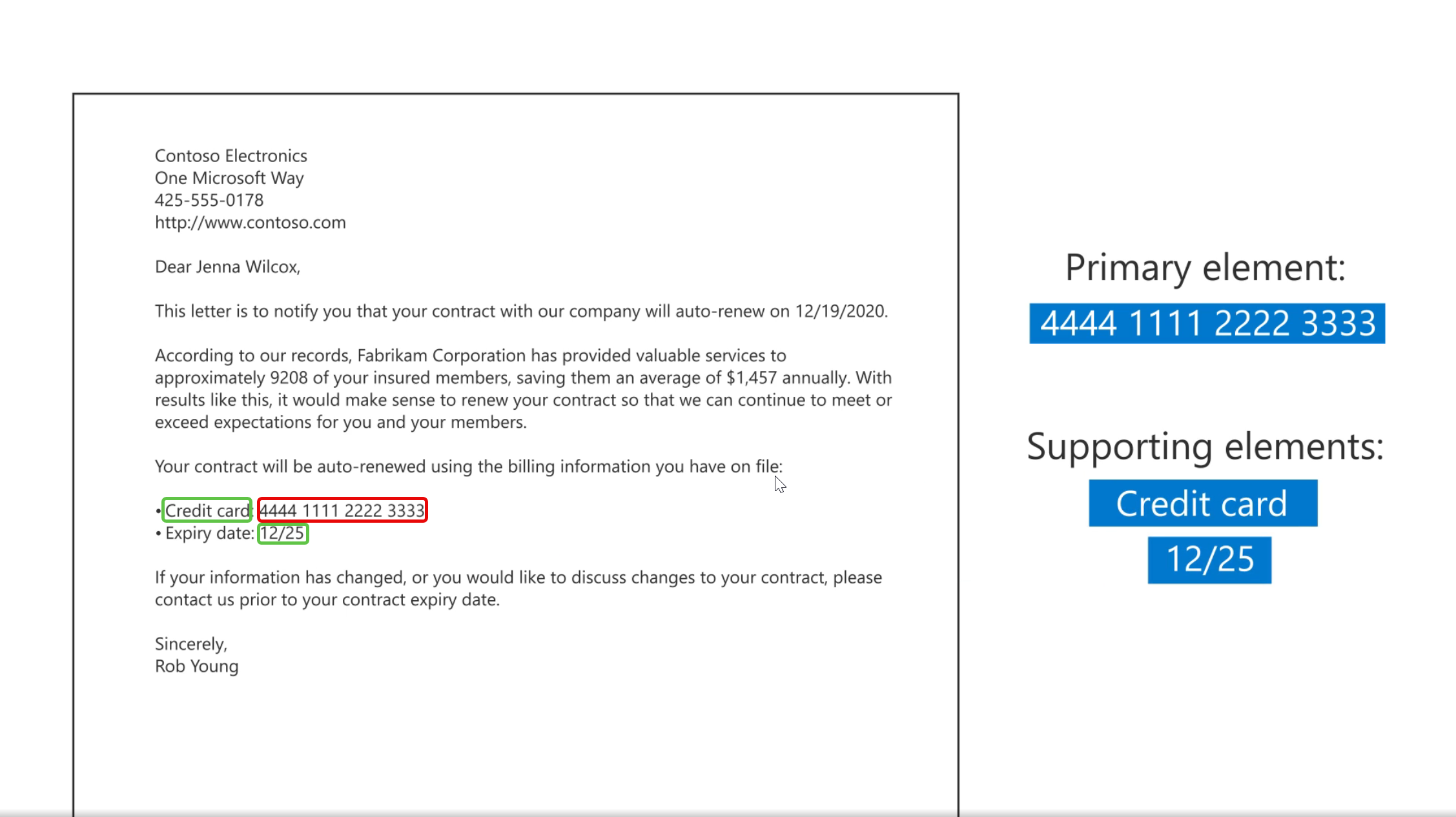
Các yếu tố bổ trợ giúp củng cố độ tin cậy cho kết quả nhận diện. Các yếu tố bổ trợ thường là những yếu tố xuất hiện gần dữ liệu chính, giúp xác nhận ngữ cảnh. Ví dụ, với số thẻ tín dụng có 16 chữ số đóng vai trò là yếu tố chính; các từ khóa như “Visa”, “MasterCard” hoặc chuỗi “Expiration Date” có thể làm thành phần bổ trợ. Hai yếu tố này sẽ giúp kết quả sẽ đáng tin cậy hơn.
Một SIT có thể có nhiều yếu tố bổ trợ.
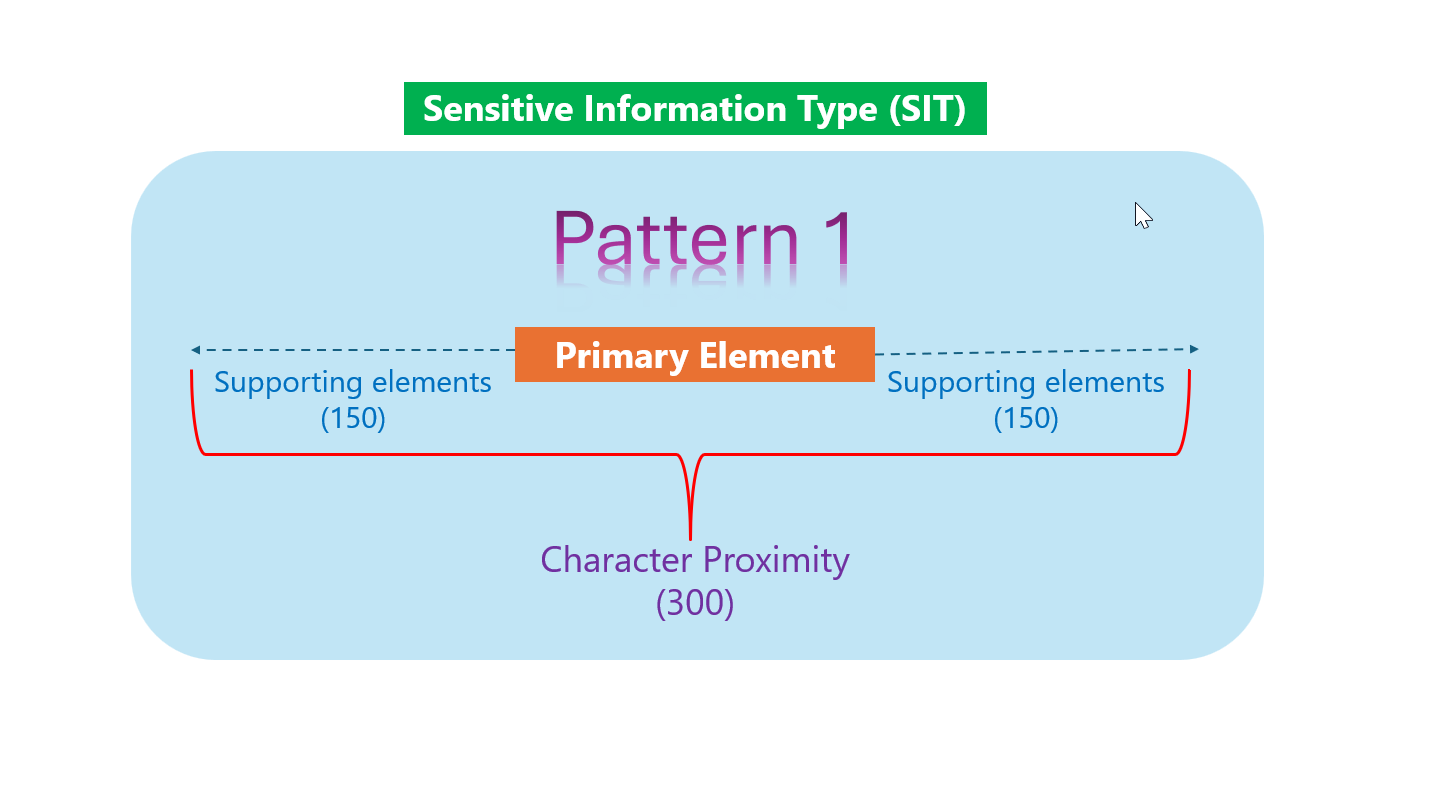
Proximity – giới hạn khoảng cách
Giới hạn khoảng cách liên quan đến yếu tố chính và yếu tố bổ trợ đã đề cập ở trên. Đây là khoảng cách tối đa (tính bằng ký tự) giữa yếu tố chính và yếu tố bổ trợ. Nói cách khác, yếu tố bổ trợ chỉ phát huy tác dụng nếu nằm trong bán kính ký tự nhất định quanh vị trí của yếu tố chính.
Thông số mặc định thường là 300 ký tự nhưng quản trị viên có thể điều chỉnh theo nhu cầu tùy loại dữ liệu. Thông số 300 của yếu tố bổ trợ đồng nghĩa 150 ký tự bên trái, 150 ký tự bên phải của yếu tố chính. Nếu một từ khóa bạn đã định nghĩa là yếu tố bổ trợ nằm ngoài phạm vi này, nó sẽ không còn được tính là yếu tố bổ trợ.
Confidence level – mức độ tin cậy

Confidence level là mức độ tin cậy của kết quả nhận diện khi mẫu nhận diện khớp. Microsoft sử dụng ba mức độ tin cậy là thấp (low), trung bình (medium), cao (high) tương ứng với các mốc ~65%, ~75%, ~85%.
Mức độ tin cậy phụ thuộc vào việc có bao nhiêu bằng chứng hỗ trợ được tìm thấy cùng với yếu tố chính. Càng nhiều yếu tố bổ trợ xuất hiện cùng với yếu tố chính, mức độ tin cậy càng cao. Chẳng hạn, nếu chỉ khớp mỗi yếu tố chính mà không có yếu tố hỗ trợ đi kèm, mức độ tin cậy của kết quả có thể bị xem là thấp.
Bạn có thể đặt nhiều mẫu nhận diện với các mức tin cậy khác nhau cho một SIT. Ví dụ khi cấu hình SIT về thẻ tín dụng
- Pattern A (High confidence) yêu cầu số thẻ tín dụng + từ “Visa” hoặc “Mastercard” + ngày hết hạn;
- Pattern B (Medium confidence) chỉ yêu cầu số thẻ tín dụng + từ “Visa” hoặc “Mastercard”;
- Pattern C (Low) chỉ cần khớp số thẻ tín dụng.
Khi quét nội dung, nếu tìm thấy dữ liệu khớp với Pattern A thì coi như phát hiện độ chính xác cao, còn khớp Pattern C thì độ tin cậy thấp hơn. Việc phân tầng như vậy giúp cân bằng giữa hai yếu tố false positive (dương tính giả – hệ thống báo có dữ liệu khớp nhưng thực tế lại không có) và false negative (âm tính giả – hệ thống báo không có dữ liệu khớp nhưng thực tế lại có). Mẫu High đòi hỏi nhiều bằng chứng sẽ giảm thiểu cảnh báo sai (false positive) nhưng có thể bỏ sót một số trường hợp, trong khi mẫu Low bắt được hầu hết trường hợp nhưng có thể bao gồm một số kết quả không chính xác.